自动化测试(Automated Testing),是指把以人为驱动的测试行为转化为机器执行的过程。往往通过一些测试工具或框架,编写自动化测试用例,来模拟手工测试过程

L.Zoe
Quick note
乾坤源码解析-概要版
乾坤源码解析
Single-Spa 痛点
single-spa就做了两件事 1. 加载微应用(加载方法还是用户自己提供的)2. 维护微应用状态(初始化、挂载、卸载)
主要的问题
1、对微应用的侵入性太强
○ 微应用路由改造,添加一个特定的前缀
○ 微应用入口改造,挂载点变更和生命周期函数导出
○ 打包工具配置更改
2、样式隔离问题
3、JS 隔离
4、资源预加载
5、应用间通信
第一个和第四个就不好解决了,这是 JS Entry 方式带来的问题
Promise对象池
1 | /** |
模块化打包工具对比
全局 window 的问题,定义的变量,函数,默认都在一个 window 作用域下. 比如1
2
3
4
5
6
7
8
9
10
11
12
13
14// a.js
var userName = '牛夫人';
console.log(userName);
// b.js
var userName = '小甜甜';
console.log(userName);
// index.html写法1
<script src= 'a.js' />
<script src= 'b.js' />
console.log(userName); // 小甜甜
// index.html写法2
<script src= 'b.js' />
<script src= 'a.js' />
console.log(userName); // 牛夫人
仅仅只是引入 a.js和 b.js两个文件的顺序不同就会导致当前页面输出不一样的值.
而且没有模块化的话很容易把业务代码写在一个 很长的 js 里.
从性能来说,这个 js 会加载很长时间, 网站性能不好.
从代码角度来说. 很容易作用域相互混淆不说, 既不利于协作,也开发效率低
所以很需要模块化打包工具
模块化打包
所以当 Rollup 这种工具横空出世,模块化打包的概念开始流行.
你写代码的时候可以按照小模块分开写, 然后用上一个带有模块化打包功能的工具.
指定一个入口文件, 模块化打包工具会自动把你的文件按照入口和入口依赖的模块,按照顺序组织好.
这个过程,写代码就像搭积木. 你的项目是由一个个模块组成的.
二 模块化标准
Commonjs
2009 年发布. Commonjs 最先开始使用是在 Nodejs 里提出的. 后来Webpack 能基于 Commonjs 打包.但是它的写法和 Nodejs 里的不是完全一样. Commonjs的写法是这样的
1 | // user.js |
从写法上来说,它和 ECMA module 挺像的.但是他俩在引入方式上是不同的. 这里后面会讲.
ES6 module(推荐)
这是 TC39 在 ECMA262 在2015 年发布的模块化标准方案. 优点多多.
优点
静态引入, 所以比较方便做静态化代码分析. 能和构建工具结合的更好.
缺点
无法根据表达式引入. 让他不能做一些更有意思的功能.
AMD
AMD 的意思是 Aysnc module AMD 和以上几种模块化的的最大区别从名字就可以看出来. 它主要是异步引入模块的.
缺点
容易陷入地狱回调. 所以现在用的人也不是很多. 这种代码维护起来比较麻烦. 容易造 bug.
Commonjs 和 ES6 module 的区别
Commonjs 必须引入整体,module 可以引入局部
比如同样的想要获得用户名 Commonjs 是这么写的
1 | let user = require('./user'); |
而 ES6 可以这样引入1
2import {getName} from './user.js'
const userName = getName();
引入方式分动态和静态
Commonjs 的引入是支持写在表达式里的. 而 ES6 module 只能在最顶级引入,且不支持表达式 Commonjs 可以这么写
1 | if(causeA) { |
而 import 的引入只能在顶级引入字符串形式的文件地址, 不能引入表达式
值映射和值复制
Commonjs 里 require 进来的文件,不管你引入几次, 其实就是第一次执行. 然后会把这个执行结果存在内存里. 等你再次 require 和调用. 其实不会再执行了,而是获取这个文件第一次的执行结果. 来做个测试
1 | // user.js |
Commonjs 的引入可以只是挂载
require 可以全局挂载不赋值变量, ES6 module 必须赋值.
有时候我们只是想执行一个 js 文件,引入进来并执行就好. 并不需要再为它赋值. Commonjs 可以单独的引用执行. ES6 module 则不可以.1
2require('./user'); // Commonjs写法
import user from './user' // ES6 module写法
三 模块化打包工具说明
开发工具演变
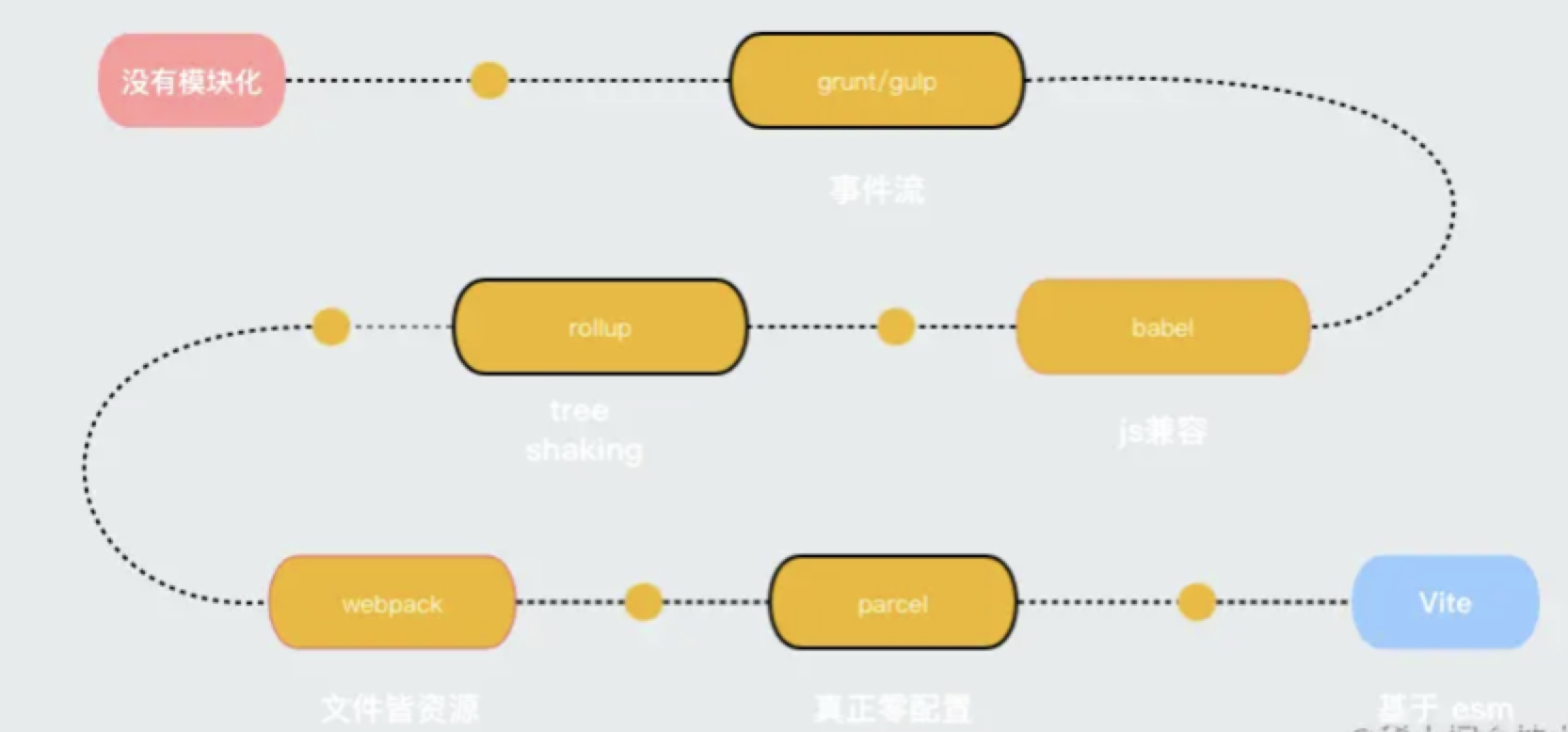
- Grunt, 比较早. 工作流打包,没有 Gulp 那么方便
- Gulp, 也是工作流. 比起 Grunt,他的 task 更方便复用
- Rollup,比较早期的模块化打包工具,就是他提出了 tree shaking
- Webpack.打包集大成者. 也是 Vue1-2 默认推荐的打包工具(目前使用最多)
- Turbopack: Webpack团队开发出的下一代打包工具,速度比 Webpack 快很多
- Vite: Vue 官方开发的打包工具.现在还支持 react 打包
观察者模式vs发布订阅的区别
一、定性区别
首先,观察者是经典软件设计模式中的一种,但发布订阅只是软件架构中的一种消息范式。所以不要再被“观察者模式和发布订阅模式xxx”这样的问题误导。
二、组成区别
其次,就是实现二者所需的角色数量有着明显的区别。观察者模式本身只需要2个角色便可成型,即观察者和被观察者,其中被观察者是重点。而发布订阅需要至少3个角色来组成,包括发布者、订阅者和发布订阅中心,其中发布订阅中心是重点。
| 观察者模式 | 发布订阅 |
|---|---|
| 2个角色 | 3个角色 |
| 重点是被观察者 | 重点是发布订阅中心 |
http和https
1、http和https区别
- http:超文本传输协议(HyperText Transfer Protocol)是用于从服务器传输超文本到本地浏览器的传输协议。可以使浏览器更加高效。以明文发送信息,若黑客截取了浏览器和服务器之间的传输报文,就可以直接获得其中的信息。
- https: 超文本传输安全协议(Hypertext Transfer Protocol Secure) 是一种通过计算机网络进行安全通信的传输协议。
https经由http进行通信,但利用SSL/TLS来加密数据包。
https开发的主要目的,是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。
简而言之: https是在http上建立ssl加密层,并对传输数据进行加密,是http协议的安全版。
简言之区别如下:
- http 是明文传输,HTTPS 通过 SSL\TLS 进行了加密
- http 的端口号是 80,HTTPS 是 443
- https 需要到 CA 申请证书,一般免费证书很少,需要交费
- http 的连接简单,无状态;https 协议是由http+SSL/TLS 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全
2、https证书签名,证书分发以及证书验证的整个过程
1)服务端人员使用RSA算法生成一个公钥和一个私钥。服务端在将公钥进行分发证书之前需要向CA机构申请给将要分发的公钥进行数字签名。
2)生成数字签名公钥证书:对于CA机构来说,其也有两个密钥,CA私钥和CA公钥。CA机构将服务端的Public Key作为输入参数将其转换为一个特有的Hash值。然后使用CA私钥将这个Hash值进行加密处理,并与服务端的Public Key绑定在一起,生成数字签名证书。其实数字签名证书的本质就是服务端的公钥+CA私钥加密的Hash值。(CA私钥负责签名,CA公钥负责验证)
3)服务器获取到这个已经含有数字签名并带有公钥的证书,将该证书发送给客户端。当客户端收到该公钥数字证书后,会验证其有效性。大部分客户端都会预装CA机构的公钥,也就是CA公钥。客户端使用CA公钥对数字证书上的签名进行验证,这个验证的过程就是使用CA公钥对CA私钥加密的内容进行解密,将解密后的内容与服务端的Public Key所生成的Hash值进行匹配,如果匹配成功,则说明该证书就是相应的服务端发过来的。否则就是非法证书。
4)验证完服务端公钥的合法性后,就可以使用该公钥进行加密通信了。
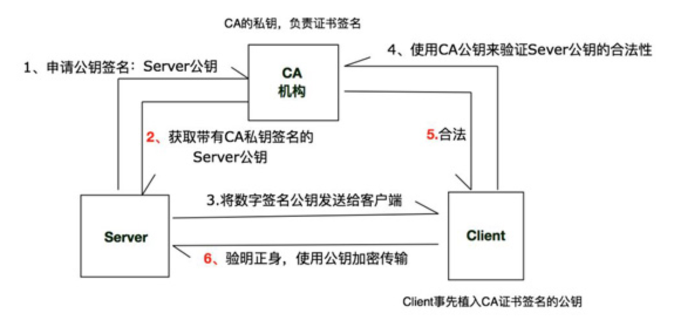
3、描述https通信过程
SSL的加密过程是RSA与AES混合进行的。简单概括一下,就是通过RSA加密方式来交换AES加解密的密钥,然后使用AES加密的方式来传输报文。大体可以分为四步:
1)客户端发起第一次握手,目的是从服务端获取数字签名证书,服务端在发送数字签名证书之前要先确认客户端的SSL版本、加密算法等信息
2)接着进行第二次握手。客户端收到证书后发起第二次握手,目的是将AES加解密使用的Key (Pre-master secret)发送给服务端(公钥进行加密的AES_KEY)。服务端收到后用私钥进行解密得出AES_KEY。这样客户端和服务端经过二次握手后都持有了AES加解密的KEY
3)当Client与Server端都持有AES_KEY后,就可以对HTTP报文进行加解密了
4)最后就是断开连接了

vite打包
vite 的文档 可以简单理解为前端工程的构建工具,vite 对自己的定义为下一代的前端工具链。
前言
- 首先为什么需要打包工具?
a. 随着es 、ts、css 预编译语言,以及vue、react 类的前端框架的快速发展,前端需要在构建阶段加入相应的编译过程才能转化为浏览器可识别的语言。
b. 同时在浏览器支持 ES 模块之前,JavaScript 并没有提供原生机制让开发者以模块化的方式进行开发。js模块化,社区多种解决方案,一直到 es6 推出 es module 规范。
c. 在开发过程中对于开发效率的问题,冷启动,热更新,以及生产环境的包体压缩,代码混淆等基于各种模块化解决方案,对应产生了各种工具,如 browserify,babel,webpack 等 - vite 为什么会出现?
a. 基于 bundle 理念的打包构建工具,对日益复杂的大型前端应用主要问题有
b. 浏览器原生支持 es 模块, node 支持 esmi. 服务启动慢 分钟级别 ii. HMR 热更新慢: 即使有 webpack 的热更新加成,项目热更新也在 8~10s
vite介绍学习
- 快 !!启动快,热更新快
基于 nobundle 理念,利用浏览器原生 ES 模块的支持,实现开发阶段的 Dev Server,进行模块的按需加载,而不是先整体打包再进行加载。
利用浏览器原生 es 模块的支持,按需加载,在构建时只需处理模块的编译而无须打包,把模块间的相互依赖关系完全交给浏览器来处理。
■ 浏览器会加载入口模块,分析依赖后,再通过网络请求加载被依赖的模块。
优势:
■ 初次构建启动快: 无包构建流程中,模块依赖分析与编译都是在浏览器渲染页面时异步处理的
■ 按需编译:在浏览器渲染时,根据入口模块分析加载所需模块,编译过程按需处理,因此相比之下处理内容更少,速度也会更快。
■ 增量构建速度快:rebuild 过程中,只需处理编译单个模块。
- Opinionated——配置简单,对于ts 、jsx、css 等支持开箱即用,免去了当 webpack 配置工程师
- 强大插件机制,以及易于扩展的 api,开发者可以自由定制构建过程,在构建流程的生命周期中,做更多的事情。同时插件兼容rollup,插件生态越来越丰富
vite 实现
Concept
基于依赖分析的打包工具,打包工具可以基于依赖分析实现 treeshking、code splitting 等优化,可以配合 runtime 代码实现 lazy load等。如 Webpack,就是通过抓取-编译-构建整个应用的代码,生成一份编译后能良好兼容各个浏览器的的生产环境代码。在开发环境流程也基本相同,需要先将整个应用构建打包后,再把打包后的代码交给dev server。
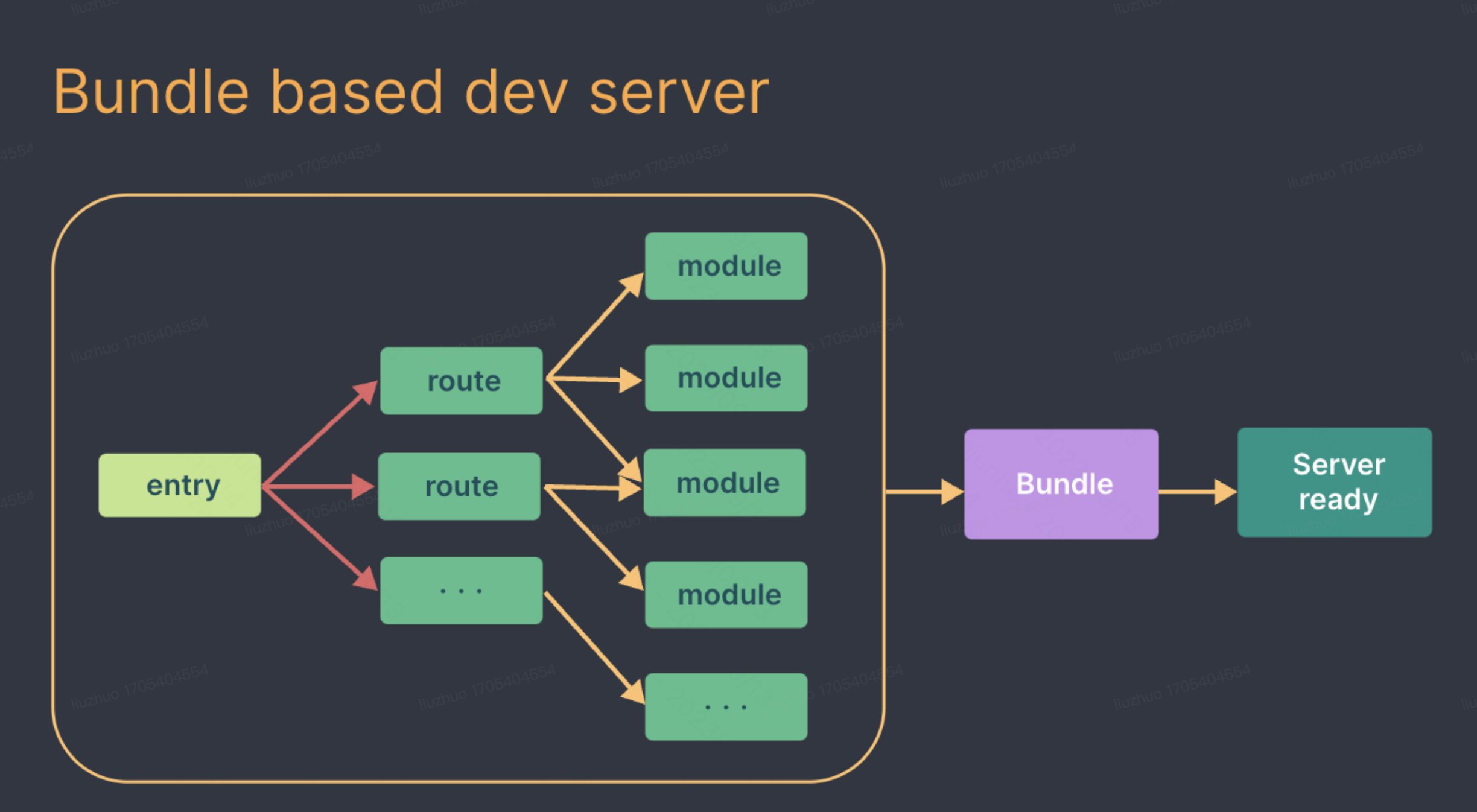
Vite直接将源码交给浏览器,实现dev server秒开,浏览器显示页面需要相关模块时,再向dev server发起请求,服务器简单处理后,将该模块返回给浏览器,实现真正意义的按需加载
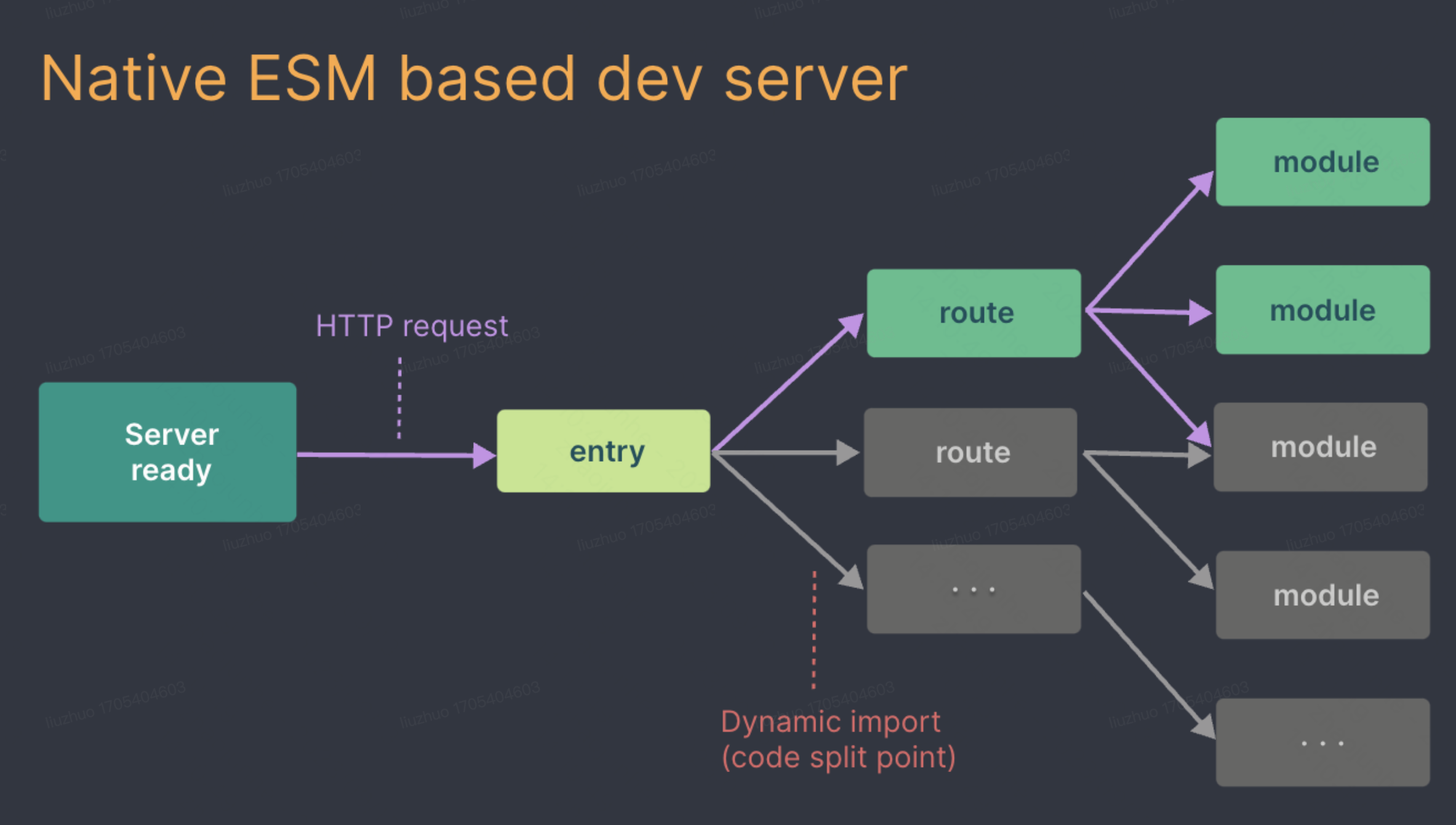
Poc
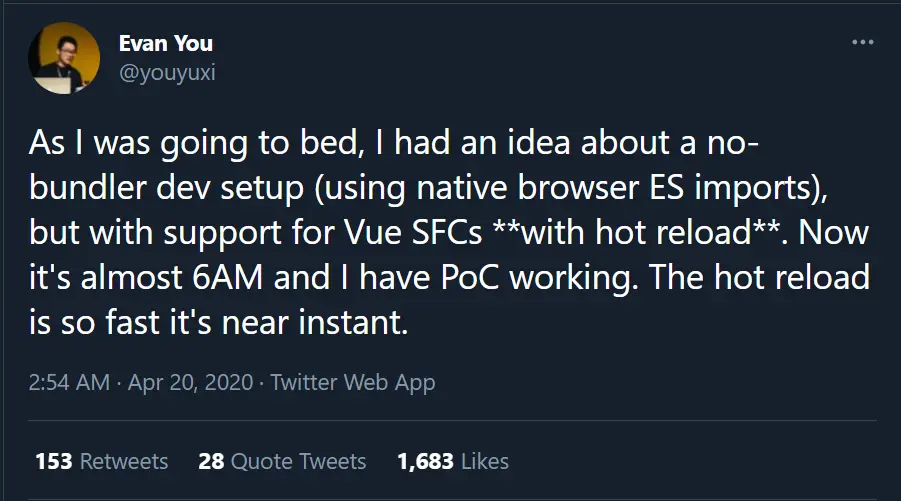
vite最开始来自己于 evan you 的一个 idea,而在这之前,他就已经有类似的想法,即vue-dev-server
想象一下,你可以在浏览器中本地导入 Vue 单文件组件……无需构建步骤。
● vue-dev-server 特点:
○ 浏览器请求导入作为本机 ES 模块导入 - 没有捆绑(bundling)处理。
○ 服务器拦截对*.vue文件的请求,即时编译它们,并将它们作为 JavaScript 发送回来。
○ 对于提供可在浏览器中运行的 ES 模块构建的库,只需直接从 CDN 导入它们即可。
○ 文件内 npm 包的导入.js(仅包名称)会被动态重写以指向本地安装的文件。目前仅vue支持特殊情况。其他包可能需要进行转换才能作为本地浏览器目标 ES 模块公开。
demo 版的 vite 分别实现了以下功能
- 将当前项目目录作为静态文件服务器的根目录
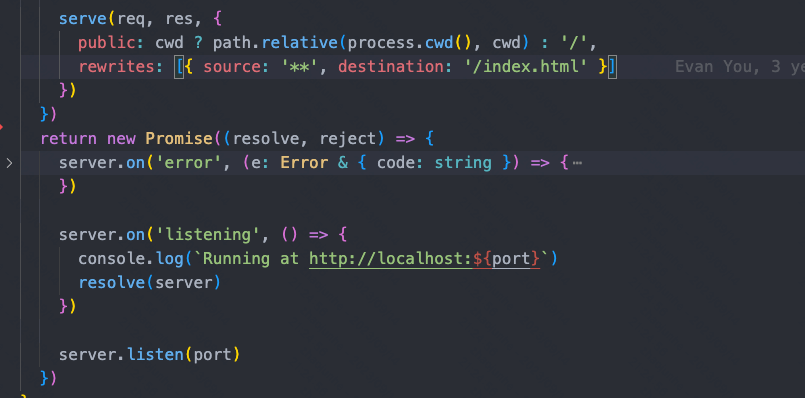
- 拦截部分文件请求
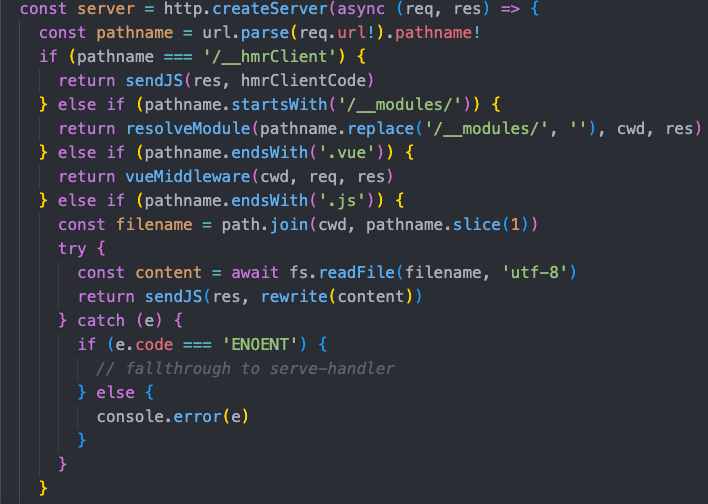
- 处理代码中import node_modules中的模块
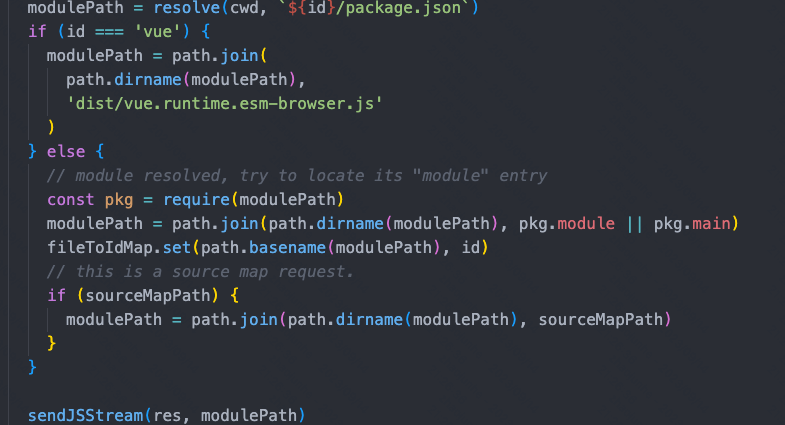
- 处理vue单文件组件(SFC)的编译
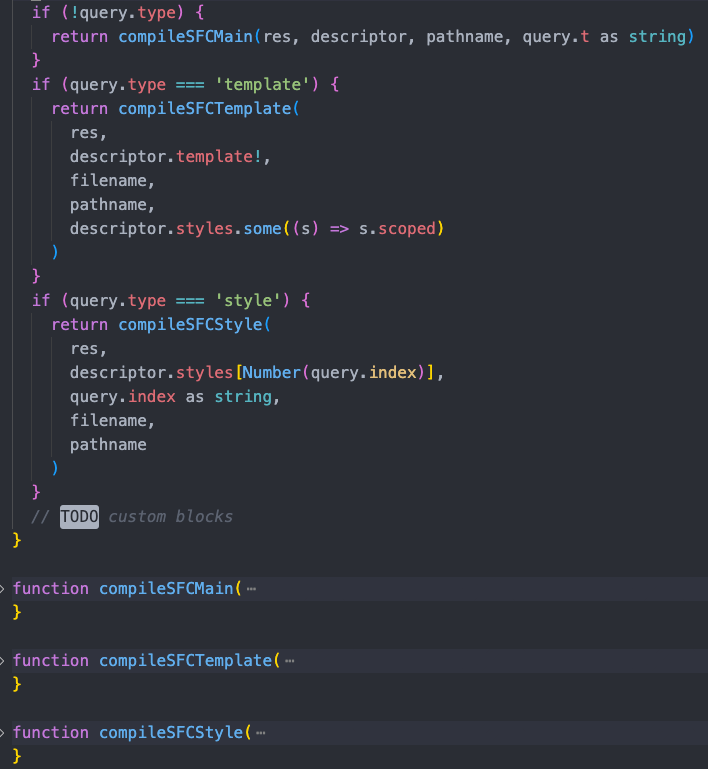
采用@vue/compiler-sfc 来解析单文件组件,将组件解析分 template、script、style 三部分 - 通过WebSocket实现HMR
Product
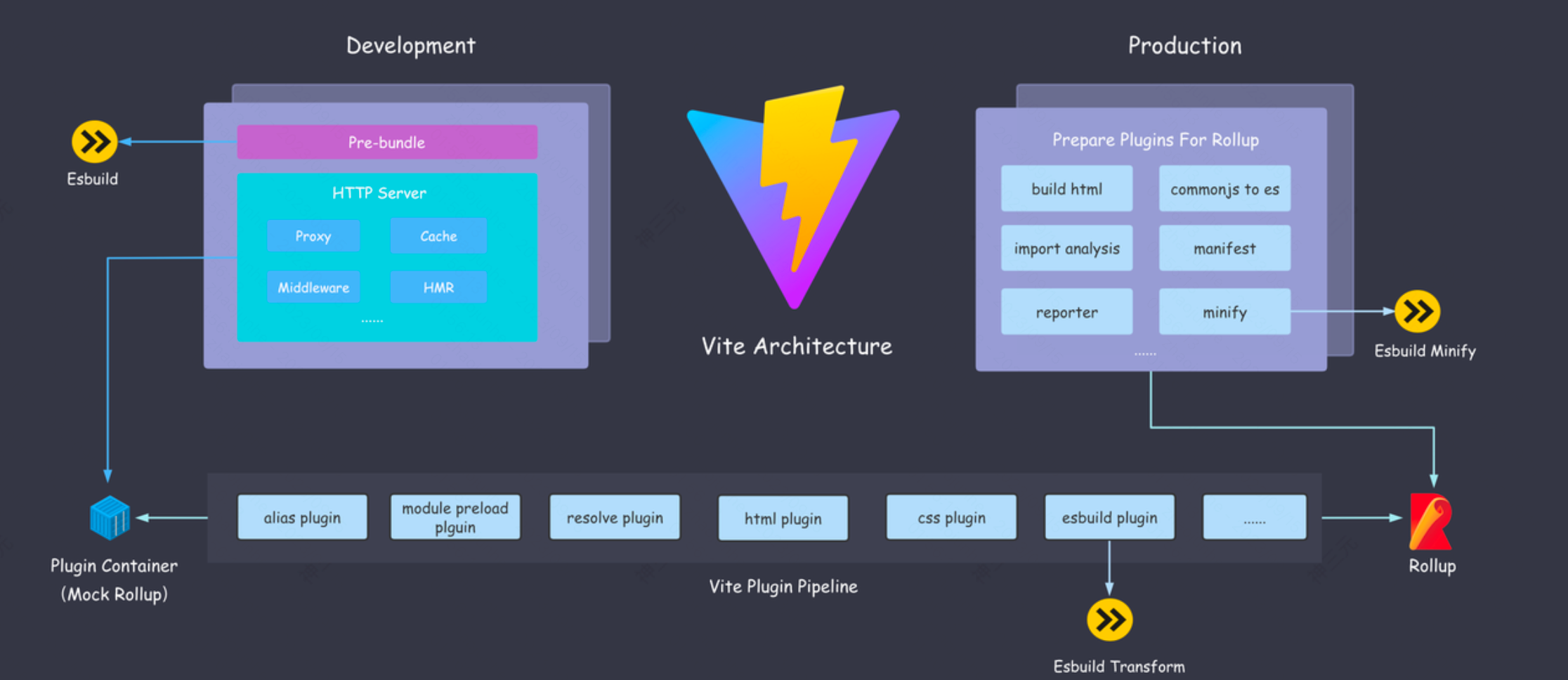
vite 的核心架构由 一个基于 ESM 的利用 esbuild 的开发服务器 和 基于 Rollup 的配置化的打包器组成,同时 vite 打造了一套基于rollup 的插件机制与生态。
依赖预构建
首次启动 vite 时,Vite 在本地加载你的站点之前预构建了项目依赖。
原因:
- CommonJS 和 UMD 兼容性: 在开发阶段中,Vite 的开发服务器将所有代码视为原生 ES 模块。因此,Vite 必须先将以 CommonJS 或 UMD 形式提供的依赖项转换为 ES 模块。
- 性能: 为了提高后续页面的加载性能,Vite将那些具有许多内部模块的 ESM 依赖项转换为单个模块。
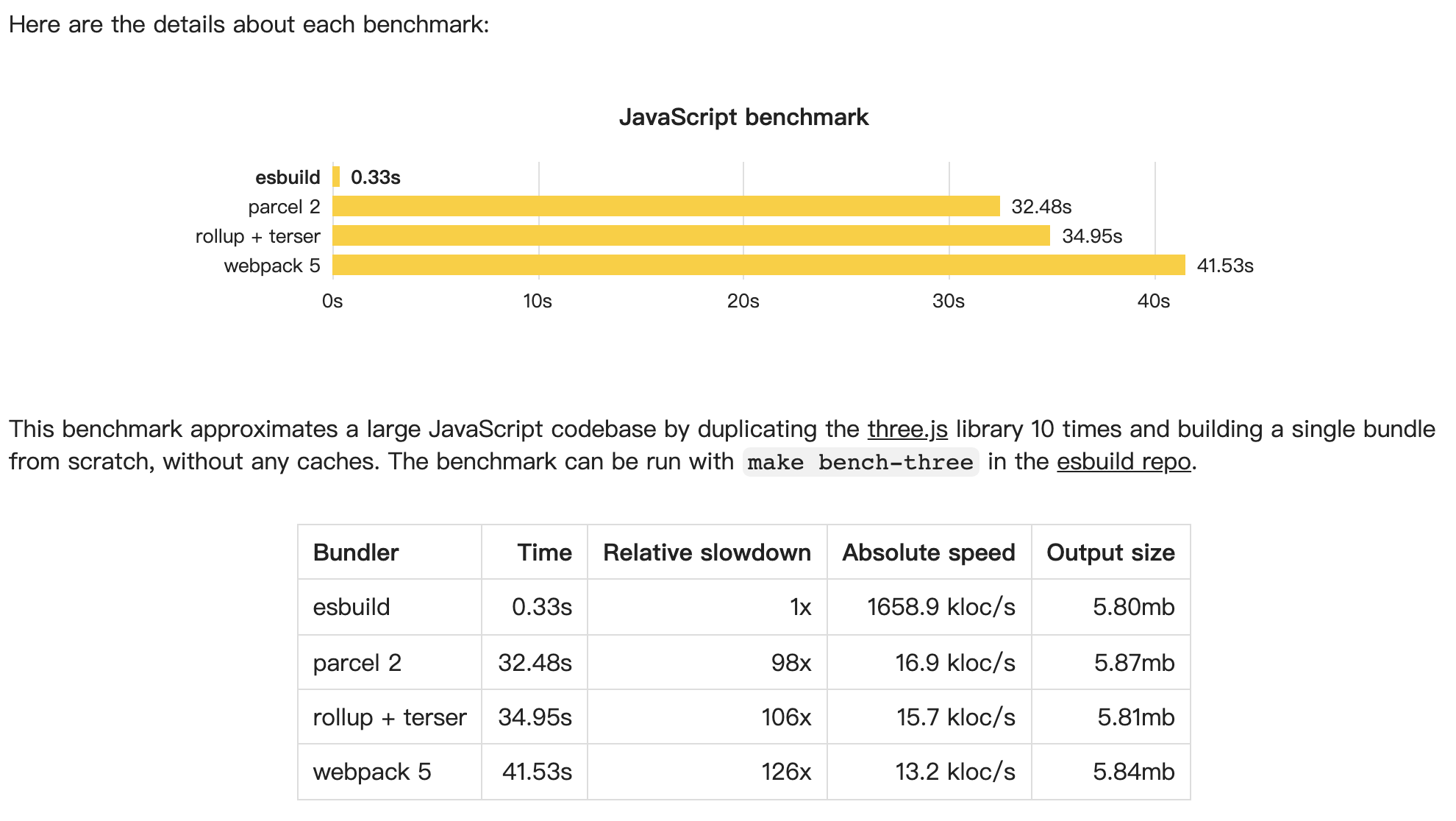
vite 是基于 no-bundle 的构建工具,在开发时按需编译而无需打包,但只针对于我们的业务代码,对于第三方依赖,vite 采用 esbuild 将依赖项转换为 ES 模块,这也是 vite 项目启动快的一个重要原因。
HMR 热更新
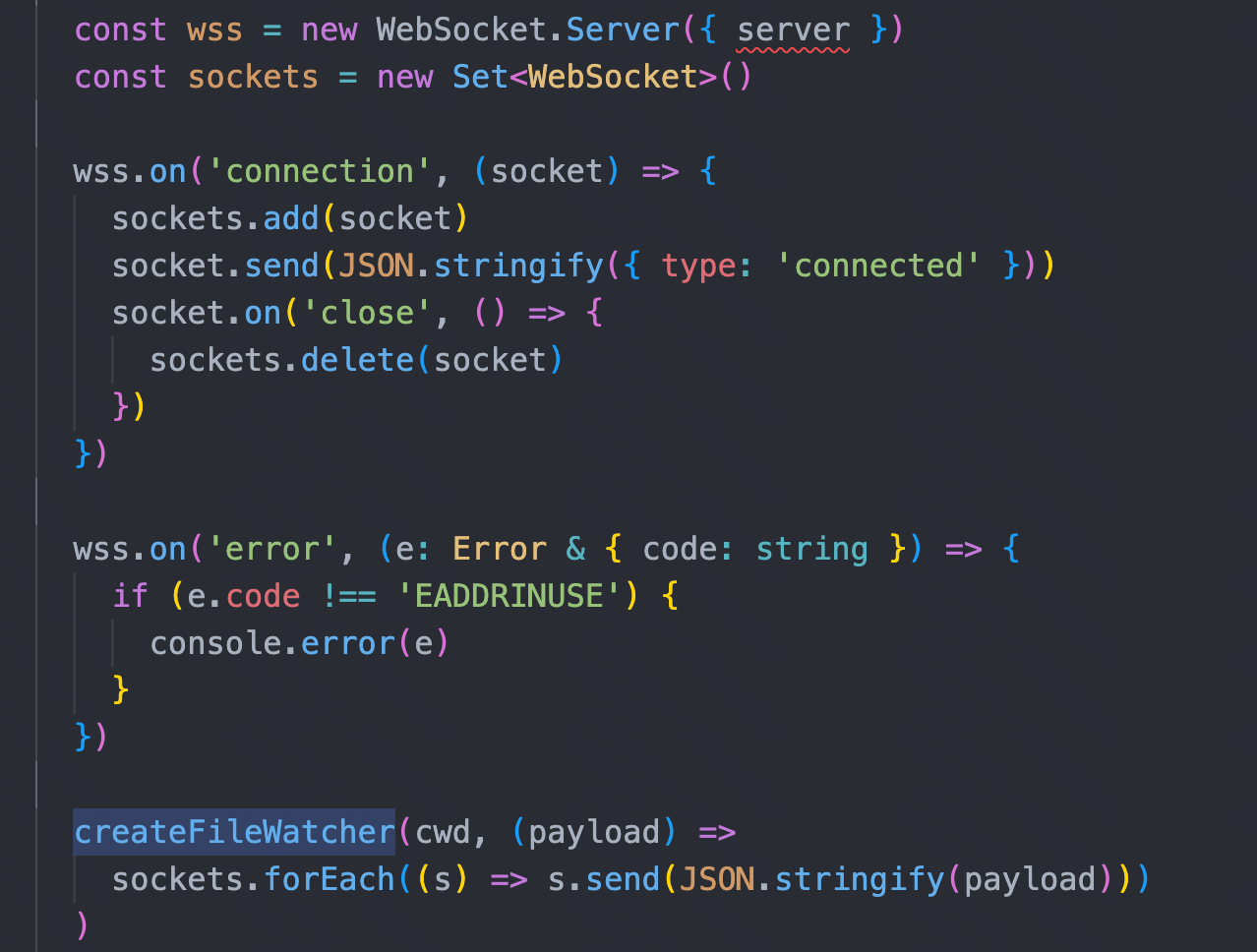
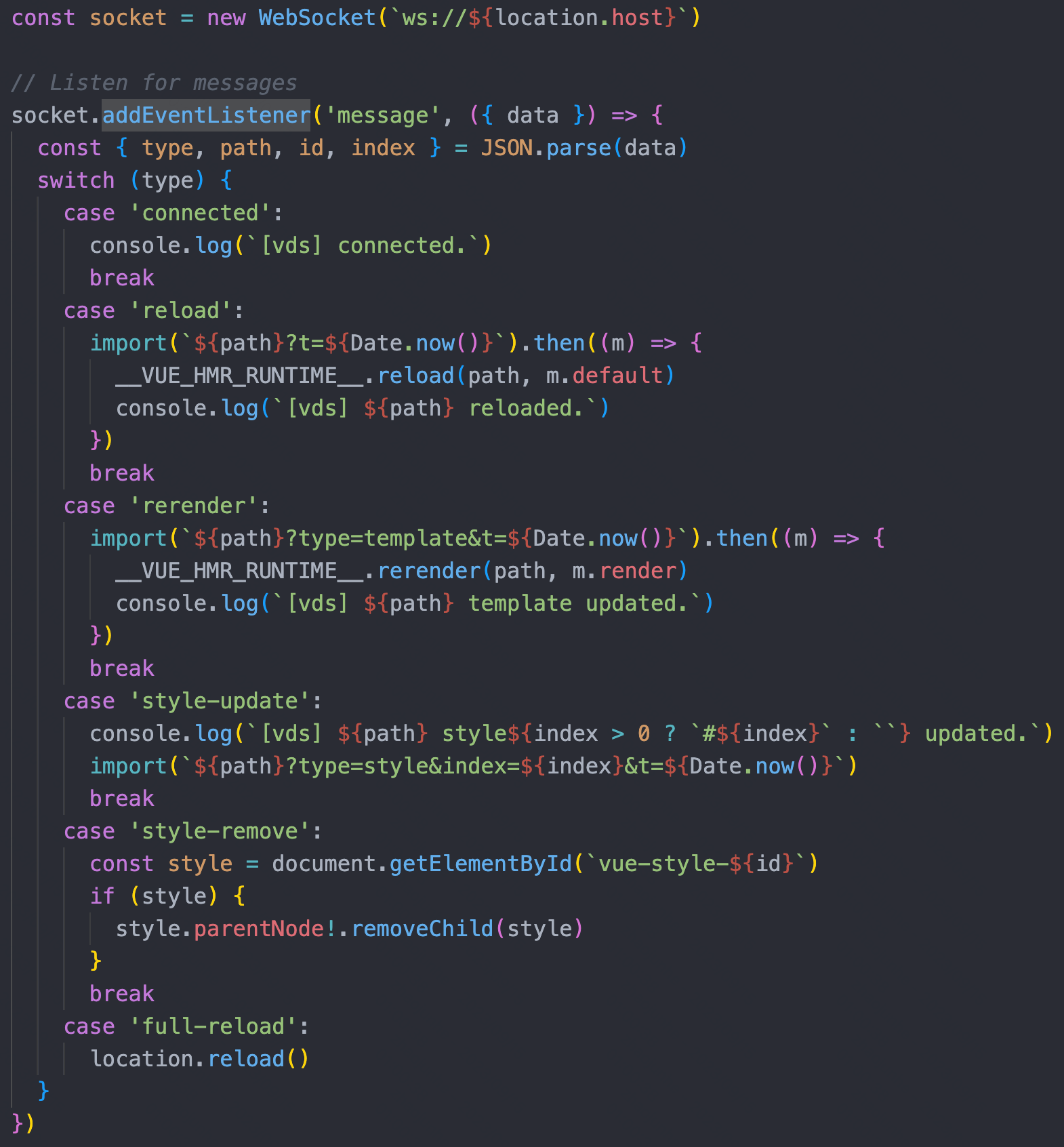
Vite 的 HMR API 基于esm-hmr 规范来实现,在客户端与服务端建立了一个 websocket 连接,当代码被修改时,服务端发送消息通知客户端去请求修改模块的代码,完成热更新。
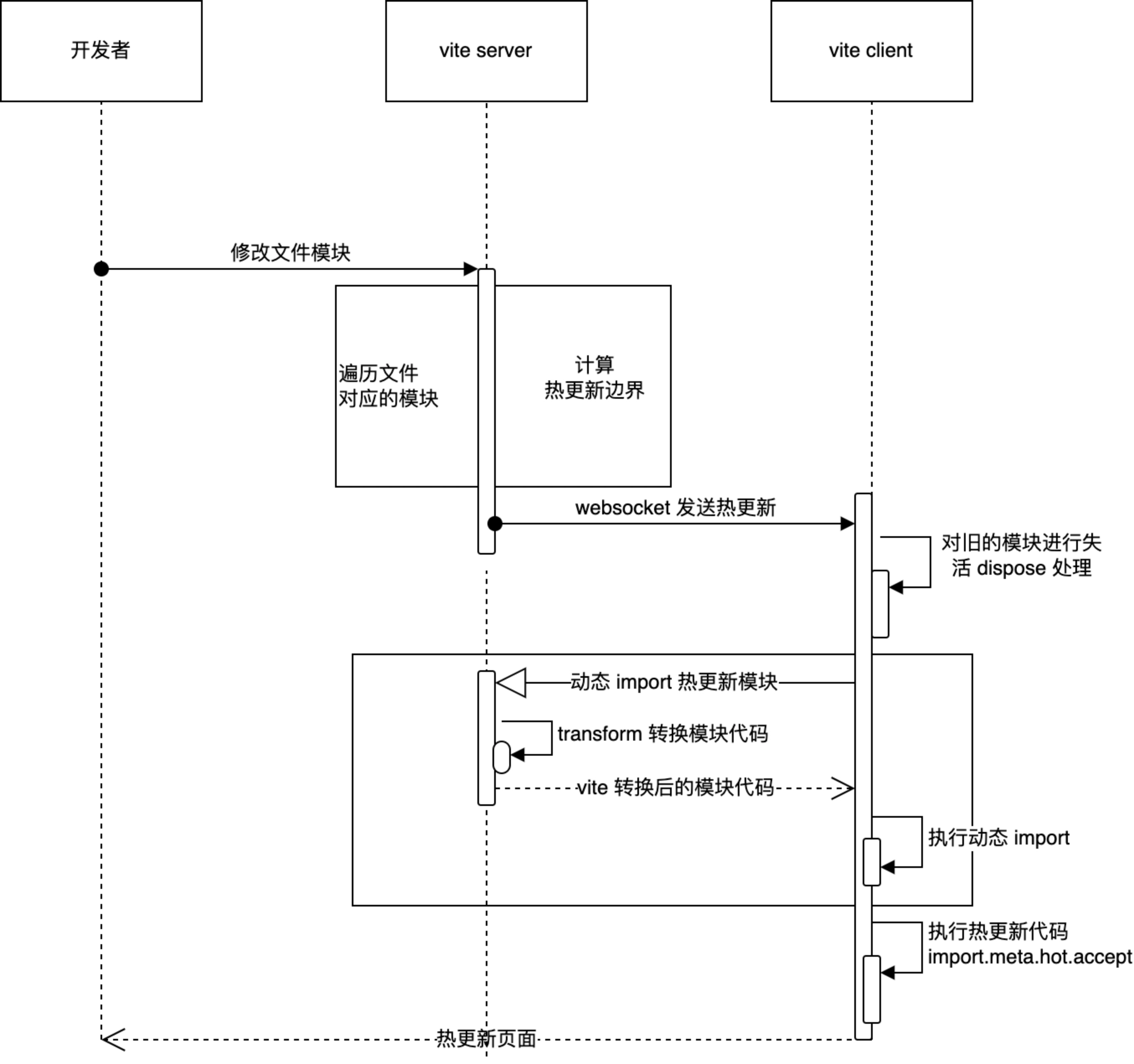
● server:服务端做的就是监听代码文件的改变,在合适的时机向客户端发送 websocket 信息通知客户端去请求新的模块代码。
● client:Vite 中客户端的 websocket 相关代码在处理 html 中时被写入代码中。
Vite 会接受到来自client 的消息。通过不同的消息触发一些事件。做到浏览器端的即时热模块更换。包括 connect、vue-reload、vue-rerender 等事件,分别触发组件vue 的重新加载,render等。
rollup
兼容 rollup 插件
- PluginContainer :用来模拟 Rollup 调度各个 Vite 插件的执行逻辑生产环境使用 rollup 打包
- 如何 同一套 Vite 配置文件和源码,在开发环境和生产环境下的表现是一致的?
- Vite 在开发模式下,模仿 Rollup 仿造出了一套拥有相同的 API 的插件架构,使得插件在两种模式下都能正常使用,保证了两种模式下 Vite 有相同的行为
- 如何 同一套 Vite 配置文件和源码,在开发环境和生产环境下的表现是一致的?
总结
- vite的核心正是依靠浏览器对ES Module规范的实现, 借助esm + nobundle 所以构建快
- 建立 在 esbuild + rollup 两大基础上
- 重点概念,依赖预构建,HMR 热更新
插件
通常的惯例是创建一个 Vite/Rollup 插件作为一个返回实际插件对象的工厂函数。该函数可以接受允许用户自定义插件行为的选项。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const fileRegex = /\.(my-file-ext)$/
export default function myPlugin() {
return {
name: 'transform-file',
transform(src, id) {
if (fileRegex.test(id)) {
return {
code: compileFileToJS(src),
map: null // 如果可行将提供 source map
}
}
},
}
}
Vite插件是一个拥有名称、创建钩子(build hook)或生成钩子(output generate hook)的对象。如果含有配置功能 ,形式为一个接受插件选项,返回插件对象的函数。在开发中,Vite 开发服务器会创建一个插件容器来调用 Rollup 构建钩子,与 Rollup 如出一辙。同时 vite 提供了自己的独有的五个钩子函数,服务于特定的 vite 目标,这些钩子会被 rollup 忽略。
| 配置 | 说明 | 与 rollup 共享 |
|---|---|---|
| name | 插件名称 | 是 |
| config | 解析 vite 配置前调用,可以自定义配置,最后会与 vite 基础配置合并 | 否 |
| configResolved | 解析 Vite 配置后调用。可以读取 vite 的配置,进行一些操作 | 否 |
| configureServer | 用来获取 Vite Dev Server 实例,添加中间件,配置开发服务器 | 否 |
| transformIndexHtml | 转换 index.html | 否 |
| handleHotUpdate | 执行自定义更新处理 | 否 |
| options | 收集 rollup 配置前,vite 服务启动时调用,可以和 rollup 配置进行合并 | 是 |
| buildStart | rollup 构建中,vite 服务启动时调用,在这个函数中可以访问 rollup 的配置 | 是 |
| resolveId | 解析模块时调用,可以返回一个特殊的 resolveId 来指定某个 import 语句加载特定的模块 | 是 |
| load | 解析模块时调用,可以返回代码块来指定某个 import 语句加载特定的模块 | 是 |
| transform | 解析模块时调用,将源代码进行转换,输出转换后的结果,类似于 webpack 的 loader | 是 |
| buildEnd | vite 本地服务关闭前,rollup 输出文件到目录前调用 | |
| closeBundle | vite 本地服务关闭前,rollup 输出文件到目录前调用 |
vite 开发时
● 服务器启动阶段: options和buildStart钩子会在服务启动时被调用。
● 请求响应阶段: 当浏览器发起请求时,Vite 内部依次调用resolveId、load和transform钩子。
● 服务器关闭阶段: Vite 会依次执行buildEnd和closeBundle钩子。
react面试题系列
1. setState是同步还是异步?
v18之前:
React是希望setState表现为异步的,因为批量更新可以优化性能。因此在React能够管控到的地方,比如生命周期钩子和合成事件回调函数内,表现为异步。
在定时器和原生事件里,因为React管控不到,所以表现为同步。
在某些情况下,我们需要立即获取更新后的状态,这时可以使用第二个可选参数callback,在状态更新后立即执行回调函数来获取更新后的状态。例如:
1 | this.setState({ counter: this.state.counter + 1 }, () => { |
v18之后:
React18之后,默认所有的操作都放到批处理中,因此setState不管在那儿调用都是异步的
如果希望同步更新,可以使用flushSync这个API。
2. React组件通信方式有哪些?
- Props: 父组件可以通过 props 将数据传递给子组件。子组件可以通过 this.props 访问这些数据。
- Callback: 父组件可以通过回调函数将函数传递给子组件。子组件可以在适当的时候调用这些回调函数,以便与父组件通信。
- Context: 上下文是一种在组件树中共享数据的方法。通过 context,可以在组件树中传递数据,而不需要在每个级别显式地将 props 传递给所有组件。
- Redux: 复杂应用全局状态管理可以使用Redux、Mobx等状态管理库,项目里一般使用React Redux或者RTK工具包。
- Pub/Sub: 发布/订阅模式是一种通过事件来进行任意组件间通信的方法,和Vue里的事件总线原理一样。
- Hooks里也可以通过useReducer和useContext来实现全局组件通信。
3. 在项目中怎么使用Redux?
Redux是一个通用的JS库,一般在React项目里不会直接使用Redux,在项目中使用的一般是react-redux。
现在React官方推荐的是RTK工具包,使用起来更简洁,不用写很多样板代码,代码可读性更好。
当然也可以根据公司的需求,自研状态管理方案。
4. Redux中间件是什么?实现原理?
中间件的本质就是个函数,在Redux每次写数据的时候执行,用来实现一些通用的功能。
常见的中间件功能包括异步中间件、持久化中间件、log中间件。
Redux中间件的实现原理和Koa中间件、Axios拦截器类似,数组里面存函数,然后compose调用中间件函数,并传递参数给中间件。
5. 函数式组件和类组件有什么区别?
- 类组件:有props、state和生命周期,可以实现复杂UI和交互。
- 函数式组件:在Hooks之前,函数式组件就是纯渲染组件,接收props返回React元素。Hooks之后,函数式组件有了能表达交互的能力。
逻辑复用:类组件可以通过HOC和Mixin实现逻辑复用,函数式组件可以通过Hooks实现逻辑复用
6. React逻辑复用方式有哪些?
Mixin:有很多缺点,已被弃用,可以不考虑。
- HOC(高阶组件):高阶组件是一个函数,它接收一个组件作为参数并返回一个新的组件。高阶组件可以将一些通用的逻辑(如:数据获取、权限验证、错误处理等)封装到一个函数中,并将其作为高阶组件的参数传递给其他组件使用,HOC一般以withXxx命名,并可以结合装饰器优雅地使用。
- Render Props:通过在组件中传递一个函数作为prop,该函数将用于渲染组件的内容。这个函数可以接收组件需要的数据和方法,并返回React元素。
- Hooks:自定义Hooks,将通用逻辑封装到useXxx函数中,可以在多个组件内使用,常见的像数据请求、表单、防抖节流、拖拽等。
xx. 使用Hooks有踩过哪些坑?
7. useRef有什么作用?
获取DOM。
存储上一次渲染的值,可以用useRef创建一个对象来存储setState前的旧值。
8. useMemo和useCallback有什么作用?
useMemo类似于Vue的计算属性。
1 | import React, { useMemo } from 'react'; |
useCallback:大多数人认为useCallback的作用是缓存函数的生成,但在实际应用中这种优化是微不足道的,useCallback真正的作用是在函数需要作为prop传递给子组件时,使用useCallback包裹可以避免子组件无谓的更新
9. React代码层面有哪些性能优化的方式?
React.memo():可以缓存组件的渲染结果,避免不必要的重渲染。它接受一个函数组件,并返回一个新的组件,新组件将只在props发生变化时才重新渲染。
useMemo和useCallback。
shouldComponentUpdate:在类组件中,可以通过实现shouldComponentUpdate()方法来判断组件是否需要重新渲染。SCU接收两个参数:nextProps和nextState,我们可以在这个方法中比较当前props和state与下一个props和state的变化来决定是否需要重新渲染组件。
使用React.lazy()和Suspense进行组件懒加载。
对于大型应用,可以使用不可变数据的三方库比如Immer.js结合shouldComponentUpdate来做性能优化。
10. 什么是受控组件和非受控组件?
受控组件和非受控组件是针对表单的。
- 受控组件:(类似于Vue的双向绑定)
React默认不是双向绑定的,也就是说当我们在输入框输入的时候,输入框绑定的值并不会自动变化。
通过给input绑定onChange事件,让React实现类似于Vue的双向绑定,这就叫受控组件。
1 | import React, { useState } from 'react'; |
- 非受控组件:
非受控组件是让用户手动操作Dom来控制表单值。用ref来获取表单元素的值
非受控组件的好处是更自由,可以更方便地自行选择三方库来处理表单。
1 | import React, { useRef } from 'react'; |
11. 什么是eject?
npm run eject命令可以将 create-react-app 创建的 React 项目里的配置文件暴露出来,以便我们自定义配置。
比如以下场景:
- 配置Less等预编译器语法。
- 使用PostCSS工具来做移动端自动适配。
- 搭建Typescript开发环境。
- Webpack优化。
12. Hooks实现原理?
- memorizedState:Fiber节点上有个属性叫memorizedState,所有的Hooks都是围绕这个memorizedState来实现的,把要存的状态和函数队列存到这个属性上,然后按需求做增删改查就行了。
- 链表存储状态:为了保证Hooks状态的序列,React采用链表来保存函数式组件的state,使用next属性来连接前后两个状态序列。
13. JSX和模板引擎有什么区别?
JSX:更加灵活,既可以写标签,也可以使用JS语法和表达式,在做复杂渲染时更得心应手。
模板引擎:更简单易上手,开发效率高,结合指令的可读性也比较好。
JSX太灵活就导致没法给编译器提供太多的优化线索,不好做静态优化,模板引擎可以在编译时做静态标记,性能更好。
JSX只是个编译工具,Vue经过一定的配置也可以使用。
14. 怎么理解Fiber和并发模式?
为什么要设计并发模式?
在React的旧版本中,当组件状态发生变化时,React会将整个组件树进行递归遍历,生成新的虚拟DOM树,并与旧的虚拟DOM树进行比较,找出需要更新的部分,然后将这些部分更新到DOM中。这种遍历方式虽然简单,但是在组件树变得非常大、复杂的情况下,会导致渲染和更新性能下降,造成页面卡顿甚至无法响应用户操作的情况。为了解决这个问题,React引入了并发模式。Fiber是什么?
- Fiber是一种数据结构,由VDOM转化生成。
- Fiber的思想是将组件树的遍历过程拆分成多个小的、可中断的任务,以实现更细粒度的控制和优化。
- 具体来说,Fiber将每个组件看作是一个执行单元,并将组件树转换成一棵Fiber树。每个Fiber节点都包含了组件的状态和一些额外的信息,例如优先级、副作用等。
- 在更新过程中,React会根据Fiber节点的优先级,将Fiber树转换成一个任务队列,然后按照优先级进行调度和执行。React还会利用浏览器提供的requestIdleCallback API来分配空闲时间,以避免阻塞渲染线程。
- 由于Fiber将组件树的遍历过程拆分成了多个小的、可中断的任务,因此React可以在需要更新的部分进行优化,从而提高渲染和更新的性能。例如,在执行更新任务时,React可以根据优先级调整任务的执行顺序,避免低优先级任务阻塞高优先级任务的执行,提高了应用程序的响应速度和性能。
React Fiber 是 React 库的内部重构,旨在改进 React 的渲染机制。它是在 React 16 版本中引入的一项重大变化。React Fiber 的目标是实现增量渲染,使 React 应用能够更好地处理大型和复杂的组件树,并提供更好的用户体验。
在 React 之前,React 使用了一种称为“栈调和”(Stack Reconciliation)的算法来处理组件的更新和渲染。这种算法在处理大型组件树时可能会导致性能问题,因为它是递归的,一旦开始处理组件树,就无法中断。这可能会导致长时间的 JavaScript 执行,从而阻塞用户界面的响应。
React Fiber 引入了一种新的渲染机制,它使用了一种称为“协作调和”(Concurrent Reconciliation)的算法。这种算法允许 React 在多个帧中分割工作,并根据优先级和时间片来调度和中断工作。这样,React 可以在多个帧之间分散工作,使用户界面保持响应,并允许其他高优先级的任务插入。
React Fiber 还引入了一种新的 API,称为“React Scheduler”,它允许开发人员控制更新的优先级,并将工作划分为不同的优先级。这使开发人员能够更好地控制应用程序的性能和响应性。
总之,React Fiber 是 React 库的一项内部重构,旨在改进渲染机制,实现增量渲染,并提供更好的性能和用户体验。它引入了协作调和算法和 React Scheduler API,使 React 应用能够更好地处理大型和复杂的组件树,并在多个帧之间分散工作,保持用户界面的响应*
15. 有了解过哪些类React框架,谈谈你对它们的看法?
Preact:可以理解为简易版React,但是和React有一样的API,性能比React还好,甚至也实现了并发模式。
Svelte:无虚拟Dom,依靠编译器和纯响应式的轻量级框架,然而性能却非常好。
SolidJS:和Svelte类似,但是SolidJS的语法更接近于React,Svelte的语法接近Vue。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
Lozoe,<br>毕业于大连皇家民族学院,目前就职于驼厂<br><br>热爱大海与冷笑话,<br/>目前是一枚前端<br/><br/>爱生活,爱健身,爱编码<br>年轻无为,卖马为生。